Mehrdad Farrokhmanesh, Shima Mehrabi (Charlotte), Azin Mirbostani (Nikolaus)Software engineer, Software Engineer, Software engineer
From Concept to Implementation: Developing a FHIR AU Core Reference Implementation with HAPI FHIR
An Overview of FHIR: Enhancing Healthcare Interoperability
FHIR, or Fast Healthcare Interoperability Resources, is a standard developed by the Health Level Seven International (HL7) organization. It aims to simplify the exchange of healthcare information across different systems. FHIR leverages the latest web standards and focuses on ease of implementation, making it a robust solution for interoperability in healthcare.
Key Concepts of FHIR
Resources: At the heart of FHIR are "resources". These are the basic building blocks that represent granular clinical data, such as patients, practitioners, medications, and diagnoses. Each resource has a defined structure and standard fields, making it easy to understand and use across different systems.
Profiles: FHIR allows for customization through "profiles". A profile is a tailored version of a resource that includes specific requirements for a particular use case or region. This ensures that FHIR can be adapted to meet the unique needs of different healthcare environments while maintaining overall interoperability.
Implementation Guides: These guides provide detailed instructions on how to use FHIR resources and profiles to address specific clinical or administrative scenarios. They serve as a blueprint for developers to create compliant and interoperable applications.
Importance of FHIR in Healthcare
FHIR is designed to address several key challenges in healthcare data exchange:
Interoperability: One of the primary goals of FHIR is to enable different healthcare systems to work together seamlessly. By standardizing how data is represented and exchanged, FHIR reduces the complexity of integrating diverse systems.
Flexibility: FHIR's modular approach allows developers to implement only the parts of the standard they need. This flexibility makes it easier to develop solutions that can evolve with changing healthcare requirements.
Modern Web Technologies: FHIR uses modern web technologies such as RESTful APIs, JSON, and XML, which are familiar to most developers. This reduces the learning curve and accelerates the development of FHIR-based applications.
Since its inception, FHIR has gained significant traction within the healthcare industry. Major electronic health record (EHR) vendors, health information exchanges (HIEs), and government health agencies have adopted FHIR as a cornerstone of their interoperability strategies. Initiatives like the Argonaut Project in the United States, the INTEROPen group in the United Kingdom, and the Sparked program in Australia exemplify the collaborative efforts to promote FHIR adoption and improve healthcare data exchange.
Reference Implementations: Bridging the Gap in FHIR Development
A reference implementation is a functional prototype that serves as a practical example of how a standard or specification can be applied in real-world scenarios. The primary audience for a reference implementation is developers who are learning about the standard. As such, it prioritizes clarity and educational value over completeness and performance. It is important to note that a reference implementation is not required to cover all aspects of a system comprehensively. The goal is to provide a representative implementation that captures the essential features and demonstrates the core concepts of the standard. This helps keep the implementation manageable and avoids unnecessary complexity. While a reference implementation may not include all possible features, it is often designed to be extensible. Developers can use it as a starting point and add additional functionalities as needed for their specific use cases.
Some FHIR reference implementations also provide a test server, offering testers a ready-to-use server for testing and developing without the need for installation.
Typical Components of a FHIR Reference Implementation
A comprehensive reference implementation often includes the following components:
Server: The core engine that processes requests and manages data according to the standard. For a FHIR reference implementation, this would be a FHIR server capable of handling FHIR resources and operations.
Data Store: A database or other storage mechanism where data is persisted. This ensures that the reference implementation can store and retrieve data as specified by the standard.
Sample Data: Pre-populated datasets that allow users to test and interact with the system.
API Documentation: Detailed documentation of the API endpoints, data models, and operations supported by the implementation, such as a Swagger endpoint.
Addressing the Need: Developing a FHIR au-core Reference Implementation
Recognizing the critical need for a reference implementation for FHIR AU-Core, we embarked on a project to develop one. Our incentive was driven by several key factors:
Facilitating Adoption: Without a reference implementation, healthcare organizations and developers face a steep learning curve. By providing a working example, we aim to lower the barriers to entry and encourage more widespread adoption of the FHIR AU-Core standards.
Ensuring Compliance: A reference implementation helps ensure that applications and systems comply with the FHIR AU-Core specifications. This compliance is crucial for achieving true interoperability and for the systems to function seamlessly within the Australian healthcare ecosystem.
Providing a Learning Tool: Developers new to FHIR or the AU-Core specifications can use the reference implementation as a learning tool. It offers a concrete example to study and learn from, which is particularly valuable for educational and training purposes.
Supporting Customization: Every healthcare organization has unique requirements. A reference implementation provides a starting point that can be customized and extended to meet specific needs, demonstrating how flexibility and scalability can be achieved within the FHIR framework.
Community Collaboration: By creating and sharing our reference implementation, we contribute to the broader community of developers and organizations working with FHIR. This collaboration fosters innovation and accelerates the development of robust, interoperable healthcare solutions.
Our primary goal was to create a fully functional, compliant reference implementation of the FHIR AU-Core specifications using the HAPI FHIR JPA server. We aimed to demonstrate best practices in FHIR implementation, provide clear documentation, and offer a flexible foundation that others could build upon.
In the following sections, we will detail the technologies and tools we used, the customization process, the features and capabilities of our implementation, and how you can use it. By sharing our journey, we hope to inspire and assist others in their efforts to improve healthcare interoperability in Australia and beyond.
Creating the FHIR AU-Core Reference Implementation: Tools and Techniques
While there are no strict limitations on the tools or techniques one can choose for implementing different sections of a reference implementation, using popular and well-supported tools can be valuable and logical. This approach provides a production-ready and extensible implementation. For our AU-Core reference implementation, we selected the HAPI FHIR server, a well-known and widely used open-source FHIR implementation based on Java.
Why HAPI FHIR Server?
HAPI FHIR server is a comprehensive, robust, and extensively tested FHIR server that has gained popularity within the community. It provides two main libraries for developing FHIR systems:
Server Library: For building FHIR servers.
Client Library: For interacting with FHIR servers.
HAPI supports two primary server models, Plain Server and JPA Server, which are described as follows:
Plain Server Model: The Plain Server model in HAPI FHIR allows developers to build a FHIR server from scratch or using any preferred REST API framework, such as Spring Boot. This model is highly flexible and delegates the interaction with endpoints, databases, and other components to the developer.
JPA Server Model: The JPA Server model, also known as the HAPI JPA Server, provides a ready-to-use FHIR server that leverages Spring Boot 3 and JPA (Java Persistence API) for database interactions. This model is designed to offer a robust, out-of-the-box solution that simplifies the deployment of a fully functional FHIR server that supports CRUD operations, validation, versioning, and more on all resources.
We chose the HAPI JPA Server model for its ease of use, robust features, and quick setup, allowing for a reliable and scalable AU-Core reference implementation with minimal effort. This model's built-in support and easy customization through Spring Boot make it ideal for our needs.
Customizing HAPI JPA Server
The HAPI server supports FHIR profile installation and customization through two main methods:
The Application Properties Configuration: The server is based on Spring Boot, and it includes numerous options in its
'application.properties'
file. This file allows for various configurations such as loading a profile, defining the data source path, and enabling validation (since validation on insert is not enabled by default in HAPI).
Interceptor Classes: Interceptors act as hooks at various points in the request flow, allowing for functionality customization. Developers can create interceptor classes and load them via the
'application.properties'
file to modify server behavior as needed.
Implementation Steps
For our AU-Core reference implementation, we followed these steps:
Setting Up HAPI JPA Server and PostgreSQL: We started by setting up a HAPI JPA server and a PostgreSQL instance. PostgreSQL was chosen due to its popularity and reliability as a database solution.
Loading AU-Core Profile: We configured the 'application.properties' file to load the AU-Core profile. At the time of writing this article, the latest published version of AU-Core is 0.4.0-preview. This version failed to load due to a dependency version resolution issue. After some investigation, we discovered that the problem stemmed from AU-Core 0.4.0-preview being based on the latest version of AU-Base, which is 4.1.0. The AU-Base version is tagged as "current" in the AU-Core 'package.json' , but it is not available in the repository. Therefore, we had to manually specify the correct version of AU-Base to ensure successful loading.
Enabling Resource Validation: We enabled resource validation before insertion by configuring the appropriate settings in the 'application.properties' file.
Writing Interceptors for AU-Core Compliance: We developed interceptor classes to ensure that only AU-Core resources are available and to disable AU-Base resources. Additionally, we developed an interceptor to enforce resource uniqueness on insert and update operations.
Populating the Database with AU-Core Examples: We populated the database with provided AU-Core example data to create a realistic testing and development environment.
Dockerizing the Solution: To facilitate easy deployment and usage, we wrote a Dockerfile and a Docker Compose file. This setup provides a ready-to-use solution that can be easily started with minimal configuration.
By following these steps and leveraging the capabilities of the HAPI JPA server, we were able to create a comprehensive and customizable AU-Core reference implementation. This setup not only demonstrates the practical application of the AU-Core standard but also provides a valuable resource for developers and organizations aiming to adopt and implement AU-Core in their systems.
Unveiling the Features: Our FHIR AU-Core Reference Implementation
Our reference implementation for the FHIR AU-Core is designed to be comprehensive, robust, and user-friendly, supporting all AU-Core profiles with full CRUD (Create, Read, Update, Delete) operations and validation functionalities. Here, we delve into the key features, compliance aspects, and extensibility of our implementation.
It offers a wide array of features aimed at ensuring seamless interoperability and ease of use:
Full CRUD Support: Our implementation supports all essential CRUD operations for AU-Core profiles. Users can create, read, update, and delete resources, making it a versatile tool for managing healthcare data.
Resource Search: Advanced search functionalities allow users to efficiently query and retrieve resources based on various parameters. This capability is crucial for applications that need to quickly access specific patient records, medications, or other clinical data.
Validation: Ensuring data integrity and compliance with the AU-Core specifications is a priority. Our implementation includes robust validation mechanisms to verify that resources conform to the defined profiles and constraints.
Preloaded Test Data: To enhance the testing and demonstration capabilities, our server comes preloaded with test data from the HL7 AU FHIR Test Data Repository. This repository provides a rich set of synthetic data that adheres to the au-core profiles, enabling users to explore and interact with the implementation without the need to input their own test data initially.
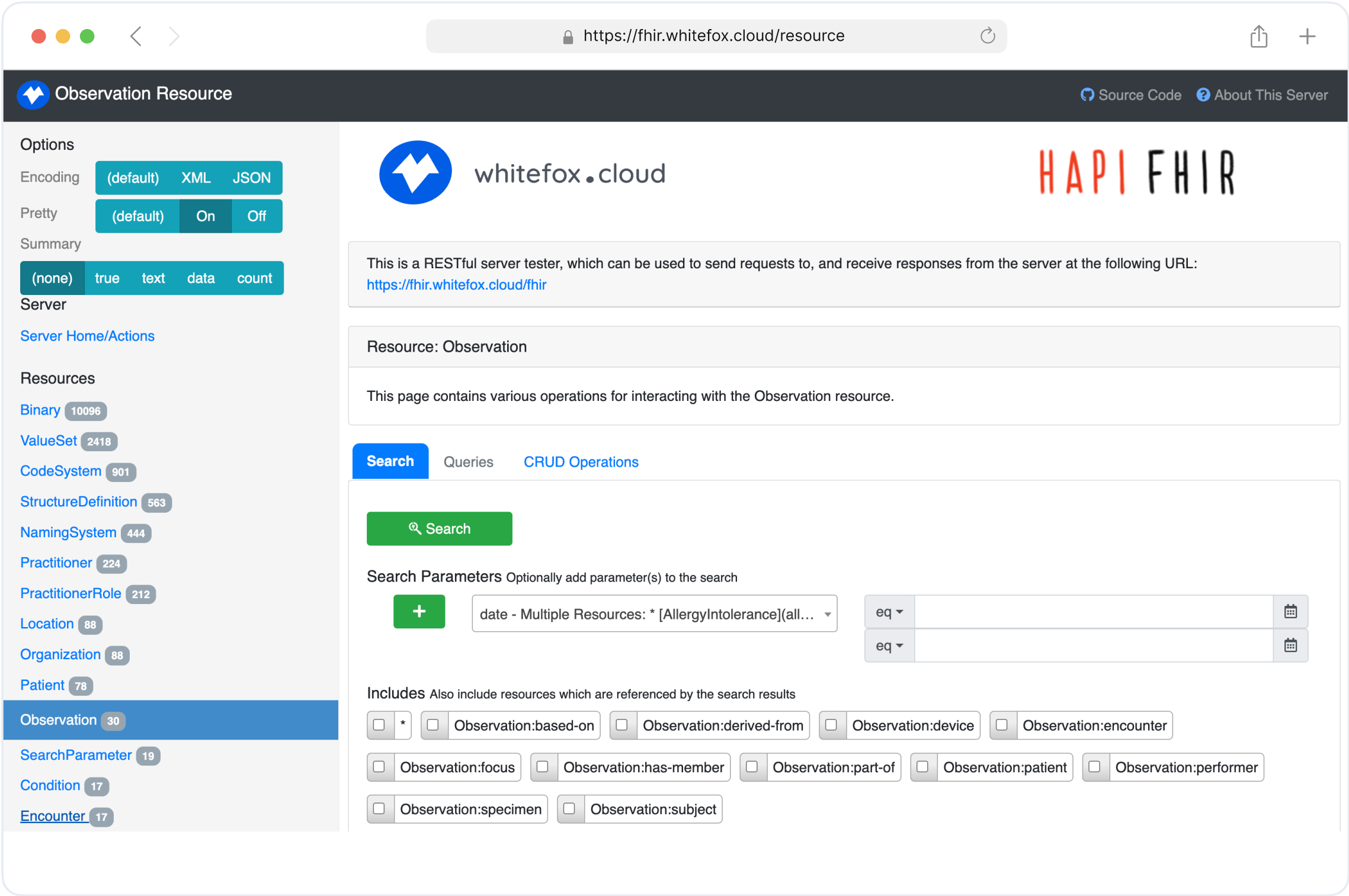
The Whitefox public FHIR test server is accessible at https://fhir.whitefox.cloud. You can use this public test server to familiarize yourself with the AU-Core specification in action and to test and validate your resources and data based on the FHIR AU-Core Implementation Guide. The source code for this server is available on our company's GitHub repository. You can use it locally or customize it to meet your specific needs. Visit our GitHub repository
Compliance with the FHIR AU-Core specifications is a cornerstone of our reference implementation. It strictly adheres to the profiles, extensions, and constraints defined in the AU-Core implementation guide. This ensures that all resources are compliant with Australian healthcare standards.
Conclusion
The development of a FHIR AU-Core reference implementation using the HAPI FHIR JPA server represents a significant step forward in enhancing healthcare interoperability within Australia. This initiative addresses the critical need for a practical, compliant example that can be utilized by developers and healthcare organizations to implement FHIR AU-Core standards effectively. By providing a comprehensive, customizable solution, we aim to facilitate the adoption of FHIR AU-Core, ensuring that healthcare systems can seamlessly exchange and utilize patient data.
Our reference implementation not only demonstrates the practical application of the AU-Core standard but also serves as a valuable resource for education and training. It simplifies the learning curve for new developers, supports compliance with Australian healthcare standards, and offers a robust foundation for further customization and development. The collaborative effort involved in creating and sharing this implementation fosters innovation and accelerates the development of interoperable healthcare solutions.
In conclusion, our work on the FHIR AU-Core reference implementation underscores the importance of practical tools and resources in achieving true interoperability in healthcare. By addressing the unique requirements of the Australian healthcare system and providing a ready-to-use solution, we contribute to the broader goal of improving patient outcomes, enhancing the efficiency of care delivery, and supporting public health initiatives. We hope that our efforts inspire and assist others in their journey toward better healthcare interoperability, both in Australia and beyond.
Streamline Your FHIR Implementation with Our Free Tools